
Micro-services for AI: Here’s Why The Best Software Engineers Don’t Use model.predict() Anymore

Real Life Analogy
Imagine you run a small T-shirt business from your home. Every time a customer in Vietnam orders a shirt, you hand-make it and send a worker directly from your house to deliver it.
You assume things are working: shirts go out, customers get them. But complaints begin to trickle in. Delays. Lost deliveries. Frustrated customers.
You hire more people to help — yet the same problem persists.
After months of digging, you discover the truth: shirts are being made and picked up, but the delivery team is overwhelmed trying to locate addresses and deliver while in Vietnam. They’re the bottleneck — and since everything was part of one giant opaque operation, it took far too long to spot the issue.
The Real Problem
It turns out the shirts are getting produced, and workers are picking them up. But the bottleneck is in delivery — your workers are struggling to locate the addresses and complete the final leg of the journey.
Over time, more and more shirts pile up. And because everything is bundled into one process, it took you months to realize where the problem actually was.
That’s What Happens With model.predict()
You might think it sounds obvious: “Of course you wouldn’t hire 20 people just to deliver the t-shirts.” Yet that’s exactly what often happens with “scaling” model.predict(): you just throw more GPUs or bigger servers at the problem. No investigation. No optimized distribution of work. Just brute provisioning.
Most teams treat their model like a magic box: model.predict(input).
But what you’re really doing is cramming the whole pipeline—preprocessing, inference, postprocessing, caching, routing, and error‑handling—into a single monolithic operation. When latency spikes or requests fail, you have zero insight into which stage is the culprit.
Why Micro-Service Architectures Are Better
1. Isolation Makes It Easier to Debug
Each stage in the application — from UI to inference — can be treated as a separate service or module.
Benefits:
- Isolated logs: Know if it’s the tokenizer, model, or formatter that’s crashing.
- Crash visibility: Catch silent errors in postprocessing or retries that .predict() might obscure.
- Monitoring granularity: Collect metrics like latency, throughput, and error rate per module.
Think of this as structured observability, not guesswork.
2. Smarter Scaling & Redundancy
In a monolithic setup, scaling means duplicating the whole pipeline. That’s like hiring more workers to fly shirts from your house again.
With micro-architectures:
- Each component can scale independently. Tokenizer CPU-bound? Add CPU pods. Model GPU-bound? Add GPU instances.
- You can define per-component autoscaling policies: different thresholds for queue depth, memory, latency.
- Add redundancy easily — fallback to a smaller model, retry a failing postprocessing step, or route traffic dynamically.
This modularity unlocks fine-grained cost control and high availability.
3. Separation of Concerns = Better Team Velocity
In a real-world setup:
- Model developers own inference logic.
- Data engineers own preprocessing/tokenization.
- DevOps handles scaling, logging, routing.
Micro-architectures let each team deploy and iterate without stepping on each other’s code paths.
From Monolith to Micro-Architecture
Monolithic Server Setup (React + Flask + SQL on Same Server)

This is the most basic architecture: frontend (React), backend (Flask), and database (SQL) are all running on the same server, and your Flask backend is what is running the model.predict().
It’s:
- ✅ Extremely simple to set up
- ✅ Fast to launch (you can even use something like Google Cloud Run)
- ❌ But not scalable or resilient under real-world load
As soon as your app grows, any spike in one part (e.g. AI inference or a long SQL query) can drag down the entire system. A sudden traffic burst could crash not just your model, but also user logins, frontend rendering, or static asset delivery.
Micro-service Architecture equivalent:
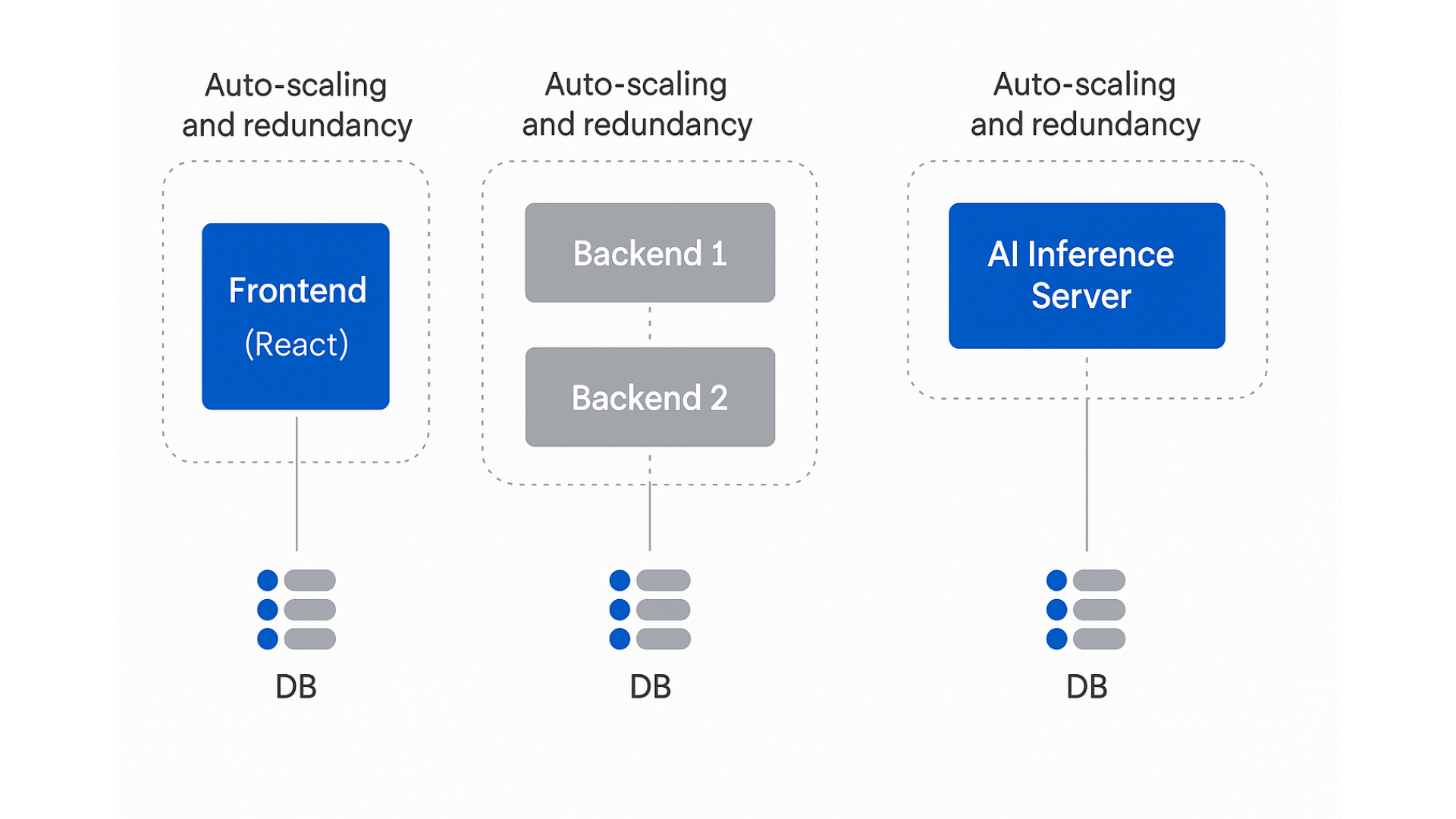
If you’re transitioning out of a monolithic architecture, don’t stress about splitting everything at once—it can involve major refactoring and lots of testing. Instead, take an incremental approach: start by separating key services into Docker containers or wrap them as external APIs. This lets you isolate workloads, monitor resource usage, and prepare for autoscaling—without overhauling your entire codebase. Think of it as decomposing complexity, one step at a time.
Convert your model.predict() to AI Micro-service
Why start with creating an AI Micro-service? Imagine that you are just trying to sign up to the platform. You experience heavy lag because the servers are busy handling AI requests. Would that annoy you as a user?
- AI models (even “lightweight” ones) are compute-hungry and latency-sensitive
- Unlike regular backend routes (like auth, payments, DB reads), AI inference can block entire threads or max out CPUs/GPUs.
- If colocated with your Flask app, AI traffic can throttle unrelated traffic — even a login request could get delayed due to an LLM running next to it
By isolating AI inference:
- You can scale independently (e.g. 1 GPU pod per 10 requests/sec)
- You reduce risk to core app features
- You gain better observability into where the bottlenecks are (backend vs model)
Eventually, you can split your database, backend, and frontend too — but start with what’s most compute-intensive.
⚠️ AI ≠ normal backend code. Treat it like a heavyweight service, not just another function.
⚡️ How To Create An AI Micro-Service (or API)
Option 1: (RECOMMENDED) HyperpodAI.com: The Fast Lane To Micro-Services
Hyperpod is probably the simplest way to turn your model.predict() into a performant, scalable micro-service.
- Export your model (e.g., TorchScript, ONNX).
- Drag and drop it into the platform.
- Click deploy — everything spins up automatically.
You get modular services for pre-processing, inference, post-processing, autoscaling, logging, metrics, routing, and cost optimisation. No infra setup and no more pesky YAMLs.
hyperpodai.com is perfect for quick prototypes and great to automatically scale existing AI workloads.
✅ Try our beta — first 10 hours are free.
Option 2:
Do It Yourself with Kubernetes
The Tried-And-True route:
- Build containers for each step
- Configure Horizontal Pod Autoscalers
- Use queues (e.g., RabbitMQ, Redis) for task coordination
- Define Service Mesh, Ingress, API Gateways
- Manage versioning, retries, load balancing
Kubernetes offers a high degree of customizability, but it can have a steeper learning curve.
Here are some great guides for Kubernetes:
- “Deploy Any AI/ML Application On Kubernetes: A Step-by-Step Guide!”: Link
- Medium tutorial “Mastering Kubernetes Deployments with YAML: A Practical Guide”: Link
TL;DR
model.predict() was great for notebooks. But if you’re deploying AI into real-world products:
- Think workflow, not function call.
- Think observable systems, not black boxes.
- Think composable pipelines, not monoliths.
Hyperpod is here to make that shift frictionless.
Try it now — your first 10 hours are on us.