
How We Beat Silicon Valley at AI Deployment: 3x Faster, 1/5 the Cost For AI Engineers
1. Introduction: One-Click Deploy Platforms
As AI adoption accelerates across industries, a new category of infrastructure platforms has emerged—“One-Click Deploy” AI platforms. These services allow developers to launch machine learning models as APIs with minimal configuration, handling the heavy lifting of:
- Auto-scaling
- Latency optimization
- Cost efficiency
- Deployment orchestration
These platforms are quickly becoming the preferred choice for AI engineers and startups who want to focus on product and model quality, rather than spending weeks building and maintaining custom inference infrastructure.
Compared to traditional cloud solutions—where teams often invest substantial time managing virtual machines, Kubernetes, and cost controls—One-Click Deploy platforms significantly reduce the operational overhead. This makes them especially attractive for:
- Prototyping new ideas
- Building minimum viable products (MVPs)
- Quickly scaling production models with limited resources
With a growing number of players in this space, it has become increasingly important to understand how these platforms compare in terms of speed, cost, and reliability.
In this report, we present a benchmarking study of four popular One-Click Deploy platforms, including our own—Hyperpod AI—to evaluate how well they deliver on the promise of fast and affordable AI deployment.
2. Benchmarking Overview
Objective
To evaluate the latency and cost efficiency of AI inference across leading deployment platforms.
Platforms Compared
- Hyperpod AI (Best Performance)
- Baseten
- Cerebrium AI
- Lightning AI
Models Evaluated
- Wav2Vec2 (Automatic Speech Recognition)
- Whisper (Speech-to-Text Transcription)
- ResNet-DUC (Image Segmentation and Classification)
- Stable Diffusion (Text-to-Image Generation)
Each model was tested with 1,000 inference datapoints, collecting latency and cost data. Average inference times were computed per model, followed by an aggregate average across all model types (a form of micro-averaging).
Each model was deployed on the selected platforms, and 1,000 inference datapoints were recorded per model. These were used to compute:
- Warm start average latency per model
- Cold start latency (where measurable)
- Hourly price of the underlying infrastructure
We then computed an aggregate average across all models per platform. This methodology approximates micro-averaging, giving equal weight to each individual inference rather than each model category.
Handling Variability in Performance
During testing, we observed that performance on some platforms varied significantly depending on the time of day and day of the week—likely due to fluctuating user demand and shared infrastructure load. To ensure fairness, we recorded performance data multiple times across several days, and for each configuration, we used the best observed performance during that period. This approach provides a more optimistic and stable view of each platform’s potential, mitigating the noise introduced by temporary load spikes.
This structured approach allows us to make an apples-to-apples comparison of how well each provider performs under optimal conditions, offering meaningful insight for developers deciding where to deploy their models.
3. Results Summary
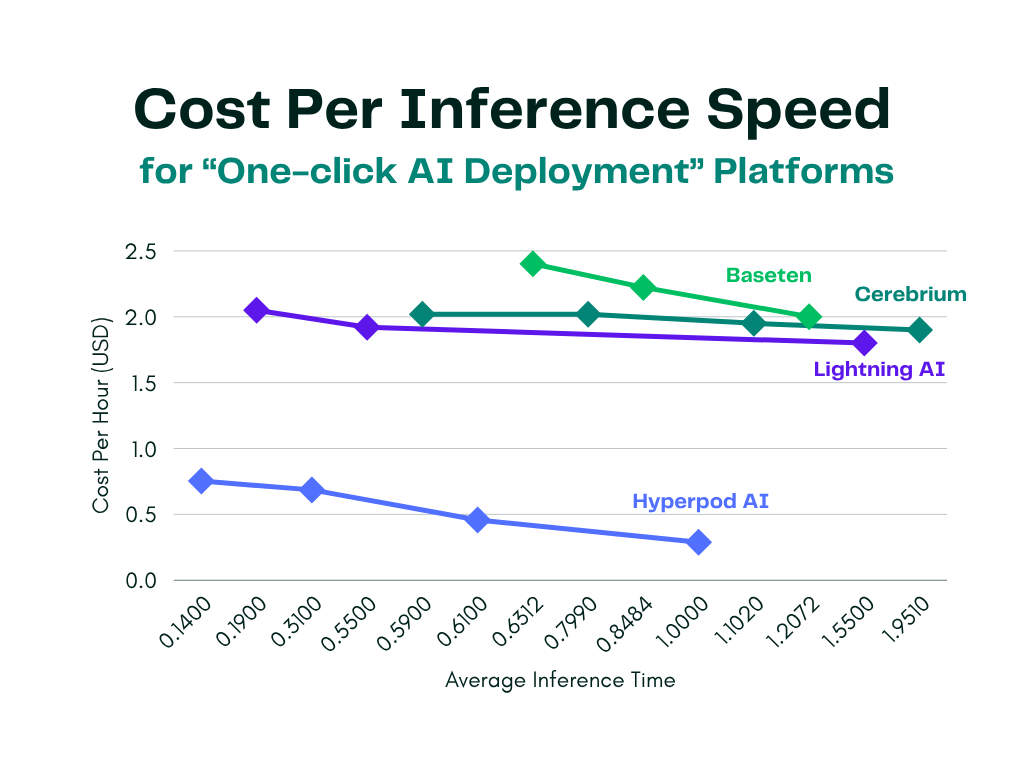
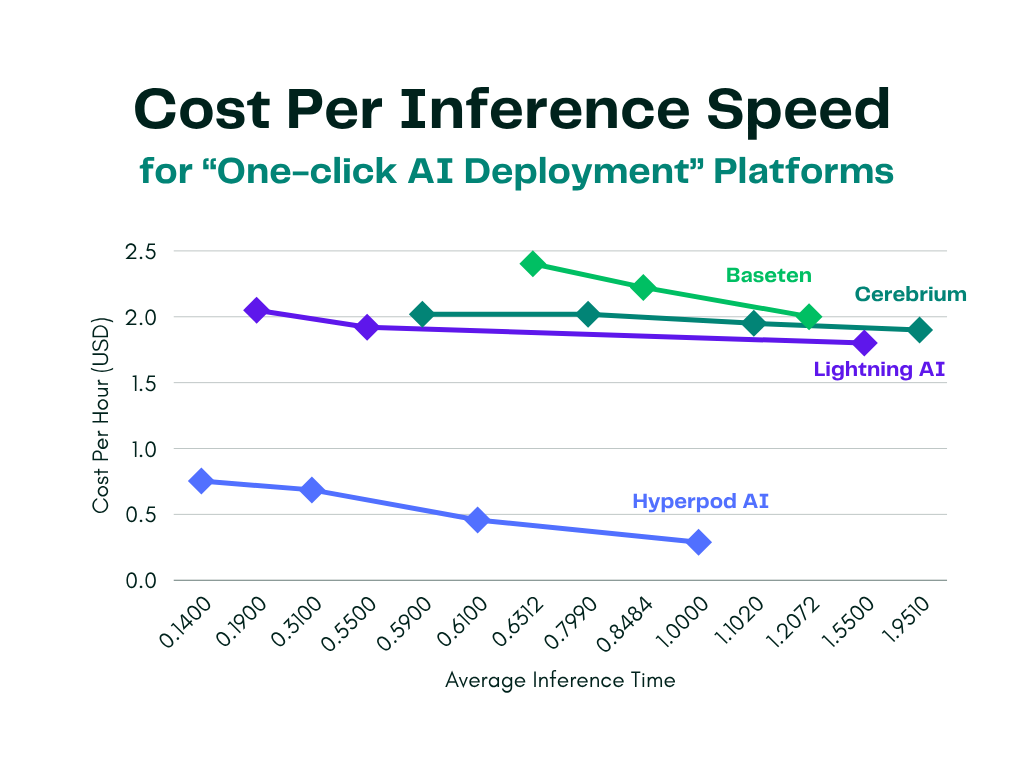
Our benchmarking clearly shows that Hyperpod AI consistently delivers faster inference at a significantly lower cost compared to leading AI deployment platforms—up to 3x faster performance for approximately 1/5 the price.
Performance Breakdown
Key Observations:
- Latency: Across warm start conditions, Hyperpod recorded inference times as low as 0.289 seconds, outperforming all compared providers across every hardware tier.
- Cost: Even at peak performance modes, Hyperpod’s pricing remains below most competitors’ mid-tier offerings.
- Cold Start Time: Hyperpod’s cold start latency was also competitive, staying under 1 second in most performance modes, whereas other providers showed cold starts exceeding 25–150 seconds, especially on Lightning AI and Cerebrium.
A100 Note on Baseten:
We attempted to benchmark Baseten’s A100 configuration over multiple days and test runs. Unfortunately, the performance was consistently unresponsive or significantly delayed, making it infeasible to produce reliable benchmark results. As such, this configuration was omitted from our comparative data table.
4. Conclusion
Hyperpod AI’s performance benchmark reinforces its position as a viable alternative to high-cost, complex AI deployment platforms. As AI adoption grows, platforms that combine simplicity, affordability, and speed will be critical to enabling the next generation of applications.
→ Visit Hyperpod AI to get started