
Deep Learning Model Prediction Using ONNXRuntime
In the age of Hugging Face and high-level APIs, .predict() has become the default way to run machine learning models. It’s easy, it works out of the box, and it hides a lot of complexity under the hood. So why not just stick with it?
Well, if you’re serious about deploying AI at scale — with low latency, high efficiency, and reliability — there’s a better tool: ONNX Runtime.
In this post, we’ll explore why model.predict() isn’t always enough, when it is the right choice, and how ONNX Runtime delivers lightweight, production-grade inference without the headaches.
👉 Related: Micro-services for AI: Here’s Why The Best Software Engineers Don’t Use model.predict() Anymore
Why This Question Matters
Modern model APIs are deceptively simple. Behind every call to .predict() is a cascade of logic:
- Sampling loops (for generation tasks)
- Attention masking
- Tokenization quirks
- Device shuffling between CPU and GPU
- Batch padding, trimming, and reshaping
These abstractions make experimentation seamless — but they also make inference unpredictable and inefficient when you’re ready to deploy.
As models get more complex and training pipelines grow heavier, .predict() carries unnecessary baggage into production.
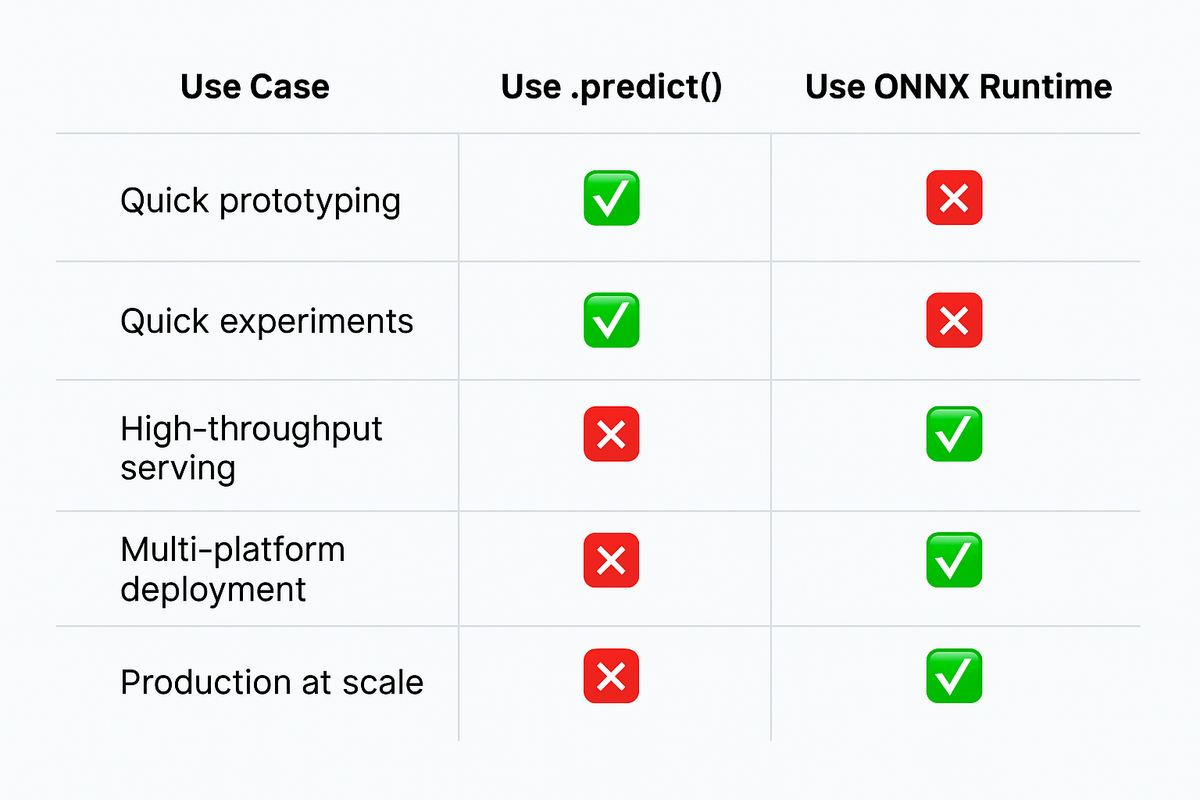
When model.predict() Is Actually Great
Let’s give credit where it’s due.
✅ Why you might choose .predict():
- You’re prototyping or debugging quickly
- You need dynamic behavior (e.g., auto-regressive generation)
- You’re running small-scale inference locally
- You’re in a research loop, not a production pipeline
It’s flexible, readable, and tightly coupled with the training framework (e.g., PyTorch or TensorFlow). If you don’t care about latency, memory usage, or scale — it’s a solid choice.
But once you care about any of those things — model.predict() starts to hold you back.
What Makes ONNX Runtime Different
ONNX (Open Neural Network Exchange) is a format that lets you export models from training frameworks into a static, interoperable graph.
ONNX Runtime is the lightweight inference engine that runs those models — optimized for speed, memory, and hardware flexibility.
Instead of dynamic execution with Python logic and framework dependencies, ONNX Runtime executes a frozen graph of computation. That means:
- All weights are frozen
- Loops are unrolled
- Dynamic ops are eliminated
- Everything is compiled into a tight, optimized runtime
Optimization Without the Low-Level Pain
ONNX Runtime doesn’t just run your model — it optimizes it.
Behind the scenes, it performs:
- Constant folding
- Kernel fusion
- Memory pattern optimization
- Operator elimination
- Hardware-specific tuning
Essentially, it compiles your model into something close to what you’d write in C++/CUDA — but you didn’t have to write any of it.
You get the speed of low-level execution without touching low-level code.
Benchmarks: ONNX Runtime vs model.predict()
Let’s look at some numbers:
These are real improvements — and they come just from exporting the model and running it with ONNX Runtime. No retraining. No model surgery.
Scaling Inference: The Hidden Superpower
Static models like ONNX are far easier to scale:
- 🧱 Run across multiple machines or containers
- 🧪 Integrate with inference-serving tools
- 🚫 No Python runtime or training framework dependencies
This is a major reason we recommend separating inference from your backend when moving to microservice architectures.
🔗 Read our full guide on scaling with micro-architectures
Other Inference Engines: A Quick Glance
ONNX Runtime isn’t alone. There are other options — depending on your stack:
Each has its place — but ONNX Runtime hits the sweet spot for simplicity, performance, and portability.
Conclusion: Use the Right Tool for the Right Job
model.predict() is fantastic — when used in the right context.
But if you’re:
- Deploying to production
- Running real-time inference
- Scaling across GPUs or nodes
- Trying to save memory, latency, or cost
Then it’s time to graduate to something better.
ONNX Runtime gives you the performance of low-level C++, with the ease of high-level Python.
It’s what modern AI infrastructure needs — and it’s easier than ever to use.
Benchmark Sources
Note: The performance benchmarks cited in this article were not generated by us.
- ONNX and NPU Acceleration for Speech on ARM — Microsoft Tech Community
- Accelerating Phi-2 with ONNX Runtime — ONNX Runtime Blog
- Optimize for Speed and Savings: High-Performance Inference — Martynas Subonis, Substack
- ONNX Runtime Python Example: Convert & Predict — ONNX Runtime Docs